
Think twice before using asyncio in Python
I have been using multithreading and multiprocessing in Python for quite some time now. Very recently I came across this library called ‘asyncio’ which seems to have caught the attention of python programmers ranging from software engineers to data scientists to ML engineers.
I desperately wanted to catch the train before it’s too late.
But the problem I picked up for solving with asyncio is one of those problems which is not optimal (no I am not talking about CPU intensive workloads) with asyncio.
Before diving into the applications, I wanted to give a brief overview of asyncio so as to make clear the differences between multithreading, multiprocessing and asyncio in Python (in case you are not already aware).
So how is asyncio different?
Multiprocessing is probably the easiest to understand. Using your program to utilize multiple CPU cores and run multiple processes in parallel.
Multiprocessing is the only truly parallel approach in Python. Multiprocessing is generally used for CPU intensive tasks such as large matrix multiplications, parallel sorting a billion integers etc.
If you are processing 2 sub-arrays in parallel processes, then at any point in time both the processes are working.
Here is an example that uses multiprocessing to find squares of each integer in an array of 100 million integers:
import random, os, sys, math
import time
from concurrent.futures import ProcessPoolExecutor
def square_array(arr:list[int])->list[int]:
return [x**2 for x in arr]
def square_array_in_parallel(arr:list[int], n:int=4, m:int=1000)->list[int]:
"""
n: number of processes
m: number of sub-arrays the array is divided into
"""
# The original array is divided into m sub-arrays and are processed
# in parallel.
# batch is the size of one sub-array
batch:int = int(math.ceil(len(arr)/m))
with ProcessPoolExecutor(n) as executor:
res:list[list[int]] = \
executor.map(square_array,
[arr[i*batch:min((i+1)*batch, len(arr))] for i in range(m)])
# Merge the processed sub-arrays after finding their squares
out:list[int] = []
for x in res:
out += x
return out
if __name__ == '__main__':
# An integer array of size 100 million with integers from 1 to 1000
arr:list[int] = random.choices(range(1,1000), k=100000000)
# Without parallel processing
start = time.perf_counter()
square_array(arr)
print(time.perf_counter()-start)
# With parallel processing
start = time.perf_counter()
square_array_in_parallel(arr)
print(time.perf_counter()-start) We divide the one big array into ‘m’ sub-arrays and then process each sub-array in parallel. Here m=1000 i.e. each sub-array is of size 100000.
With 100 million integers, the time taken by the sequential code is around 52s, while the parallel code takes 33s.
In multithreading, we use a single process only but we can create multiple threads running in single process. In Python, due to the Global Interpreter Lock, although we can create multiple threads in a process, but at any given point in time, only a single thread is running (i.e. can access the variable and function stack of the process).
Multithreading is thus useful for I/O intensive tasks such as downloading files over network, writing to files or databases, socket communication etc.
For e.g. if we are using 2 threads to download multiple images in parallel, when thread A sends the request to fetch one image, it will then wait for the bytes to be transferred over TCP completely before picking up its next url.
Meanwhile, thread B can initiate the request to download its image.
Thus at any instant of time, either thread A is initiating HTTP request and thread B is waiting for its image to be downloaded or thread B is initiating HTTP request and thread A is waiting for its image to be downloaded.
Thus, only one thread is actively running in the process at a time. Thus multithreading is not truly parallel.
import random, time, os, sys, requests, math
from concurrent.futures import ThreadPoolExecutor
def fetch_url_data_sync(url:str)->None:
try:
requests.get(url)
except Exception as e:
print(e)
def fetch_sync(urls):
for url in urls:
fetch_url_data_sync(url)
def fetch_threaded(urls:list[str])->None:
# Create a pool of 10 threads, only one will run at any time.
with ThreadPoolExecutor(10) as executor:
executor.map(fetch_url_data_sync, urls)
if __name__ == '__main__':
# Read list of urls from text file
urls_file:str = 'urls.txt'
with open(urls_file, "r") as f:
urls:list[str] = f.readlines()
urls = [url.replace("\n", "") for url in urls]
# Sample n urls from the list. The list contains 1 million urls
n:int = int(sys.argv[1])
urls = random.choices(urls, k=n)
# Without multithreading
start = time.perf_counter()
fetch_sync(urls)
print(time.perf_counter()-start)
# With multithreading
start = time.perf_counter()
fetch_threaded(urls)
print(time.perf_counter()-start)With 100 image urls, the non-threaded version of the code takes 52 seconds while the multithreading version takes only 3 seconds.
Why do we need 10 threads in the pool, when only 1 thread is running at any time?
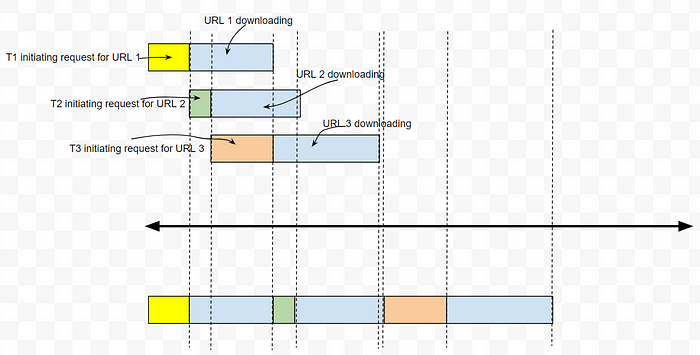
The above time diagram shows what really happens with 3 threads T1, T2 and T3 (above) vs. no multithreading (below). The total time taken should ideally decrease by adding more number of threads to the pool.
But since there is overhead in creating and destroying threads, creating more threads beyond certain number do not improve the performance and they start degrading beyond that.
Using a thread pool i.e. a fixed number of threads for any number of URLs somewhat fixes this issue. Without threadpool, after URL 1 is downloaded, thread T1 is killed and we will create a new thread for a new URL. But with a thread pool, after URL 1 is downloaded, T1 is assigned a new URL.
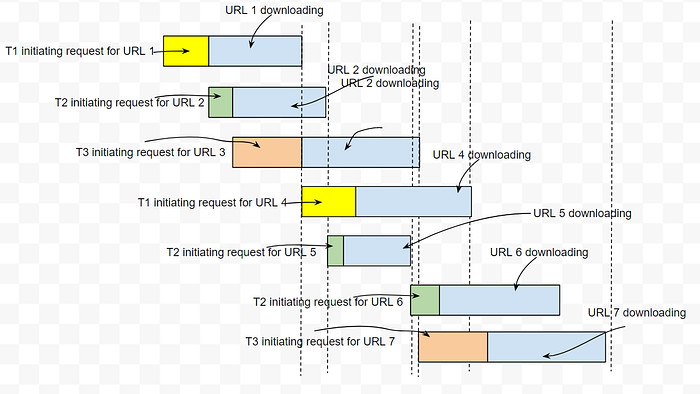
So where does asyncio fit in?
In asyncio, we have only a single process and a single thread.
There is an event scheduler known as the “Event Loop”. Think of the event loop as a circular queue.
When the thread T is waiting for the URL 1 to be downloaded, the event scheduler assigns URL 2 to thread T and while URL 1 is being downloaded, T can start initiating request for URL 2 and then the event loop will assign the next URL to T.
When URL 1 is completely downloaded, the event loop will make T come back to any code required to run after URL 1 is downloaded and ask T to execute any callbacks if present and so on. Thus the single thread T will hop to and fro between multiple tasks until all tasks are completed.
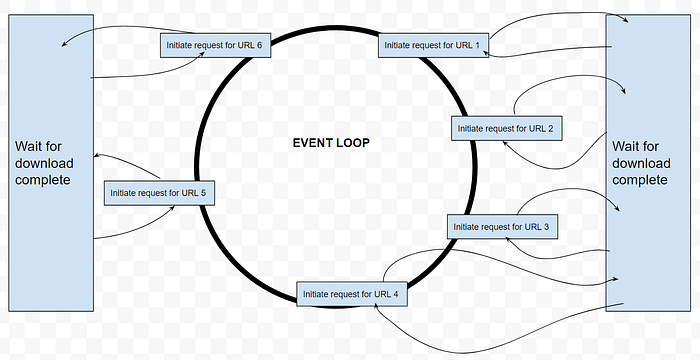
In other words asyncio facilitates asynchronous programming i.e. fire and forget.
As compared to multithreading there is not much overhead of creating and destroying threads.
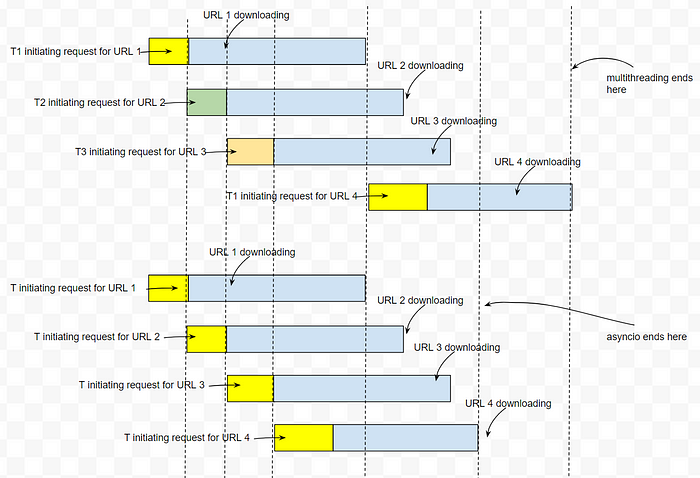
Can there be a scenario where multithreading is better than asyncio?

Till URL 4, both multithreading and asyncio requires same time, but for URL 5, asyncio starts at a later time than multithreading and thus finishes at a later time.
In asyncio, a task can only start when the previous task in the queue ‘pauses’ but in multithreading, a task can start if there is any idle thread.
Can there be a scenario where asyncio is better than multiithreading?
In multithreading, for the 4th URL, it starts only after 1st URL is completely downloaded because there are no more available threads since each thread will only stop after its task is completed.
Whereas in asyncio, the 4th URL starts after the initiation for the 3rd URL completes and is waiting to be downloaded.
Understanding the basic skeleton of an asyncio code
*Note — Implementations here uses version 3.10 of Python. If you are using older versions such as < 3.6, some syntaxes might differ.
I will not go into the details of the internal workings of asyncio or how to write your own async version, but would like to give a general idea about how to use asyncio.
In asyncio, if we have to make some function asynchronous i.e. we call this function and move on, then we have to define this function with an ‘async’ keyword:
async def async_fire_and_forget(*args):
# do something
returnIn order to call an ‘async’ function from another function, we call the async function using the ‘await’ keyword. The function which calls ‘await’ also needs to be declared ‘async’.
async def async_task(*args):
# do something before
result = await async_fire_and_forget(args)
# do something after
returnWhen the ‘async_task’ function is called, after the thread encounters the ‘await’ statement. The thread will return the control back to the event loop, which will then decide which task to pickup next.
Note that the the execution of ‘async_fire_and_forget’ may not have completed yet and thus it is not necessary for the thread to wait for it to be completed.
But after it is completed, the thread resumes anything after the await statement as usual. But in this example, there is only one task ‘async_task’
For e.g. if there are 2 tasks i.e. we want to call ‘async_fire_and_forget’ multiple times with different arguments:
async def async_task(*args):
# do something before
result = await async_fire_and_forget(args)
# do something after
return
async def async_task_multiple(*args1, *args2):
# do something before
result1 = await async_task(args1)
result2 = await async_task(args2)
asyncio.gather(result1, result2)
# do something after
returnIn the above example, we have 2 tasks. Thus when the thread is working on the 1st task with args1, it encounters await statement and returns control back to event loop. The event loop then starts on 2nd task i.e. args2 and the same thing happens again.
To collect the results of all the tasks, we usually call with asyncio.gather(), which is similar to thread.join() in multithreading.
To make it more clearer, in our example, async_task could be a task to download images from a list of urls. So if we have 100 urls, args1 could be the list of 1st 50 urls and args2 the remaining list of 50 urls.
Important: call await only on IO intensive tasks.
The “good” scenario
asyncio is most useful when used with time consuming I/O tasks such as downloading images over the network.
Here is an example with Python:
import asyncio
import random, string, time, os, sys, requests, math
from aiohttp import ClientSession, ClientResponseError
async def fetch_url_data_async(session:ClientSession, url:str)->None:
# fetch url
try:
async with session.get(url, timeout=60) as response:
# This is a time consuming task hence await
await response.read()
except Exception as e:
print(e)
async def fetch_async(urls:list[str]):
tasks = []
async with ClientSession() as session:
for url in urls:
tasks.append(fetch_url_data_async(session, url))
# All tasks submitted to event loop and then event loop
# schedules these tasks
await asyncio.gather(*tasks)
if __name__ == '__main__':
# Read list of urls from text file
urls_file:str = 'urls.txt'
with open(urls_file, "r") as f:
urls:list[str] = f.readlines()
urls = [url.replace("\n", "") for url in urls]
# Sample n urls from the list. The list contains 1 million urls
n:int = int(sys.argv[1])
urls = random.choices(urls, k=n)
# asyncio version
start = time.perf_counter()
asyncio.run(fetch_async(urls))
print(time.perf_counter()-start)
# normal version no asyncio or multithreading
start = time.perf_counter()
fetch_sync(urls)
print(time.perf_counter()-start)
# multithreading
start = time.perf_counter()
fetch_threaded(urls)
print(time.perf_counter()-start)As before, running the above code with 1000 image urls, it takes around 239 seconds for the normal version, 38 seconds with multithreading and 23 seconds with asyncio. So asyncio is the clear winner here.
The “bad” scenario
The first problem, that I picked up to solve with asyncio was not downloading the images from the urls. It was writing data to files.
I have a list of string messages and need to log them to different local text files based on hash(message)%N, where N is the number of text files for logging. This is also an I/O problem (disk I/O).
One such strategy is to write each string, line by line in a different asyncio task. Thus the asyncio event loop will have as many tasks as number of strings to write.
import asyncio
import aiofiles
import random, string, mmh3, datetime, time
# asyncio common lock object for all tasks
asyncio_lock = asyncio.Lock()
async def write_file_async(file:str, msg:str):
# lock file before writing to it
async with asyncio_lock:
async with aiofiles.open(file, "a") as f:
await f.write(f"{msg}\n")
async def write_async(strs:list[str], num_files:int):
# define the tasks for the event loop
tasks = []
for mystr in strs:
key = mmh3.hash(mystr, signed=False) % num_files
tasks.append(write_file_async(f"{key}.txt", mystr))
await asyncio.gather(*tasks)You may ask why do we need locking with asyncio since it is single process and single threaded.
It can happen like this:
- Thread sends the request to the OS to append message and returns control back to event loop. The OS needs to go to the location in the disk to write the message.
- While the OS is doing disk operations, the event loop picks up the next task which again writes to the same file (because hash is same).
- Since the information regarding the next available position to write data is not updated yet, the thread’s next request will try to use the same position (or some overlapping position) in the file as the previous request.
Thus although asyncio is single threaded, if we are writing data to the same file over multiple tasks, there is a chance that messages get overlapped and gibberish is written. Thus we need locking for shared resources.
The above asyncio approach is much slower than writing sequentially without asyncio. This is because with locking in place, it essentially becomes synchronous plus the additional overhead of event loop task management which is not present in synchronous writes.
The next best approach is then to not use locking but change the approach to first collect all strings with same hash and then write them together in one file. Thus there will tasks equal to the number of files to write.
Note that this approach will not work for streaming data as we have to pre-collect all messages with the same hash.
async def write_file_async(file, msgs):
async with aiofiles.open(file, "w") as f:
await f.writelines(msgs)
async def write_async(strs:list[str], num_files:int):
# collect all messages with same hash first
key_strs = {}
for x in strs:
key = mmh3.hash(x, signed=False) % num_files
if key not in key_strs:
key_strs[key] = []
key_strs[key].append(x + '\n')
# define the tasks for the event loop
tasks = []
for key, msgs in key_strs.items():
tasks.append(write_file_async(f"{key}.txt", msgs))
await asyncio.gather(*tasks)In this approach too, if the number of files to write are small and/or the messages to write are small (few bytes only per line), then also synchronous writes is pretty much comparable to asyncio.
This could be due to multiple factors:
- Since we are writing to local files, the time it takes to write the message to the file and return back to the event loop i.e. the await f.writelines(msgs) to return is smaller than the time it takes for the event loop to assign the next task to the thread.
- aiofiles internally uses threadpool, thus the overhead of creating and destroying threads are also accounted for.
We can verify the 1st point by adding some fractional asyncio.sleep after f.writelines() in the asyncio code and time.sleep for synchronous writes.
async def write_file_async(file, msgs):
async with aiofiles.open(file, "w") as f:
await f.writelines(msgs)
# adding asynchronous sleep
await asyncio.sleep(0.001)
def write_file_sync(file, msgs):
with open(file, "w") as f:
f.writelines(msgs)
# adding synchronous sleep
time.sleep(0.001)Some Key Takeaways
- Use asyncio only when the number of tasks to complete are high.
- Use asyncio only when the tasks are time consuming i.e. the time taken to complete a task is much higher than the time taken for the event loop to pickup and assign the next task to the thread.
- There could be scenarios where multithreading or normal synchronous operations wins over asyncio. Evaluate before finalizing the codes.
- Avoid local file I/O with asyncio.
References
- Async IO in Python: A Complete Walkthrough — Real Python
- How the heck does async/await work in Python 3.5? (snarky.ca)
- Coroutine (dabeaz.com)
- python — AIOFiles Take Longer Than Normal File Operation — Stack Overflow
- Working with Files Asynchronously in Python using aiofiles and asyncio (twilio.com)
- python — How does asyncio actually work? — Stack Overflow
