
Understanding and Implementing Raft Consensus Protocol in Python
Distributed systems in general follow the CAP Theorem (Consistency, Availability, Partition Tolerance) which states that any distributed system will satisfy at-most 2 out of 3 i.e. a system which satisfies strong consistency and high availability will not satisfy partition tolerance similarly a system which satisfies partition tolerance and strong consistency will not satisfy high availability.
In order to build a CA compliant Distributed Hash Table (DHT) i.e. it satisfies strong consistency and high availability, we will use a very popular consensus protocol named Raft.
The idea of high availability w.r.t. a DHT can be expressed as follows:
- All SET, GET, DELETE etc. operations are always successful, but it does not guarantee anything on the latency numbers.
Some scenarios where we don’t achieve high availability:
- If the data is only on a single machine, then if that machine crashes all key value pairs will be lost since it is in-memory.
- Even if we store the data on disk as well as RAM, if the machine crashes, the system will be become unavailable for queries. Right way to do is probably have multiple machines or replicas. The number of replicas chosen is such that the probability that all machines crashes together is negligible or almost 0.
- Even with multiple replicas, the queries from client will be sent over to only a single server. What if that server crashes? We can always retry with a different server.
The idea of strong consistency w.r.t. a DHT can be expressed as follows:
- If a key-value pair is SET at time T, then at any time >T, unless we SET another value for the same key, any GET query for key will return the same value.
- Similarly, if a key is DELETE-d at time T, then at any time >T, unless we SET the same key, any GET query for key will return empty results.
Note that the above 2 are pretty obvious, if we have a single machine system. But for high availability we chose to have multiple replicas (above).
Assuming that the data for DHT is replicated across 5 machines, what can possibly go wrong?
- During SET at time T, only 3 out of 5 machines were updated (maybe they were busy or temporarily crashed), but during GET at time T+1, the query lands up on one of the 2 machines which were not updated.
- Even if we use the same server for SET as well as GET (since the problem became prominent because GET landed on a different server than SET), there is no guarantee that after SET at time T, at time T+1, the server crashed and stopped responding, then to maintain high availibility we have no choice other than trying a different server.
So here how Raft solves these problems (on a high level):
- Raft has a single leader thus all SET and GET operations land on the same server i.e. the Leader, in order to achieve strong consistency.
- Now what if after SET, the leader crashes or becomes un-responsive ? Raft chooses a new leader from the remaining replicas. But this leader is chosen in such a way that all SET operations from previous leader are already present in the new leader, thus it has the most updated state and any GET operations after T, will always return the same value.
- In order for at-least one replica to have the most updated state before the current leader crashes (so that it becomes a future leader), Raft ensures that the current leader successfully replicates its own data (for each query) to at-least 3 out of 5 i.e. (N+1)/2 servers before returning to client (it counts itself as one).
- Now for the next voting term, server A receives a vote from server B only if the data in A is at-least as updated as the data in B. During voting, a server becomes a leader when it receives at-least 3 votes out of 5 (including own).
- Thus there would be at-least one server which was most updated before leader crashed and also voted for the new leader and if a server has voted for a new leader it implies that the data in the new leader is also most updated else it would not have received vote from one of the most updated servers. - In order to prevent losing data in the event of a crash, the DHT is persisted in a commit log file on disk. Even before updating own hash table, the leader updates its own commit log and then updates the commit logs of the other replicas, so that in the event of a crash, one can recover the hash table by replaying the commit logs.
Python is not the most favorable language to implement Raft (or rather productionizing) because multithreading plays a heavy role in Raft and due to the Global Interpreter Lock, Python is single threaded. Although we can create multiple threads but at any given time only a single thread is operational.
But for demonstration purposes, it is good enough.
Raft as we all know has multiple features:
- Leader election
- Log replication
- Addition of replicas dynamically
- Log compaction
In this post we will focus on the 1st two features: Leader election and Log replication.
Assuming that we want to create 2 partitions of the hash table i.e. the total data of the hash table is divided into 2 equal parts. Now if each partition has say 3 replicas each, then we would like to represent the configuration as a list of list in Python:
[['20.230.215.164:5001', '20.9.197.71:5001', '20.98.88.12:5001'], ['20.3.189.101:5001', '20.83.242.58:5001', '20.111.37.99:5001']]Each item is IPv4:Port in the lists.
We will use a simple hash based allocation of data in the partitions. Something like hash(key)%2.
There are several reasons for doing partitioning, two of the most important are:
- Distributing load — If all keys are in same partition, all requests will come to the same cluster (in fact same leader), thus it will be ‘overworking’. Having N partitions ensures, that approximately 1/N of the keys land up on one cluster.
- Accomodating more data — Assuming that we can accomodate 1 billion keys with one partition (due to memory and throughput constraints), with N partitions we can accomodate 2N billion keys.
Whenever we talk about consensus protocol, it is applicable for a single partition i.e. the algorithm that allows all the replicas for a given partition to reach the same final state.
Each replica in a partition has the following important attributes:
- state — Each replica in a partition has 3 possible states: Follower, Candidate and Leader.
- election_timeout — A Follower starts a new election if it does not receive message from Leader for election_timeout interval. On start of new election its state changes to Candidate.
- current_term — Whenever a Follower starts a new election, the current_term increments by 1.
- voted_for — In a given term, its the id of the server a Follower or Candidate voted for. A server can vote for at-most one server either self or some other server in each term.
- votes — Set of all servers that voted for this server in the current_term
- leader_id — The id of the server which won the vote in current_term and became leader.
- commit_index — The last index or the line number in its commit log.
- next_indices — Its an array corresponding to each replica. next_indices[i] is the index (or line number) in the commit log of server with id ‘i’ from where the log of current server and server with id ‘i’ starts to differ i.e. from index 0 to index next_indices[i]-1, the logs for the current server and server ‘i’ are exactly the same.
Here is a diagram showing how Leader Election happens with 3 replicas (for replica 1):
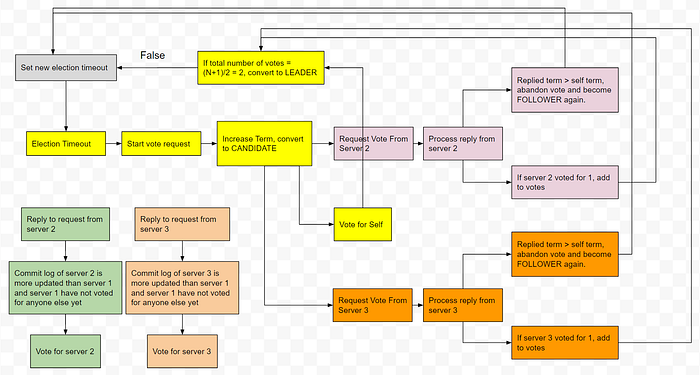
The above schema assumes there are 3 servers and the leader election protocol at server 1 is shown above. The same protocol holds true for the other two servers.
Each color coding represents a parallel path and can be implemented in a different thread or process.
Defining the Raft Class:
class Raft:
def __init__(self, ip, port, partitions):
self.ip = ip
self.port = port
self.ht = HashTable()
self.commit_log = CommitLog(file=f"commit-log-{self.ip}-{self.port}.txt")
self.partitions = eval(partitions)
self.conns = [[None]*len(self.partitions[i]) for i in range(len(self.partitions))]
self.cluster_index = -1
self.server_index = -1
# Initialize commit log file
commit_logfile = Path(self.commit_log.file)
commit_logfile.touch(exist_ok=True)
for i in range(len(self.partitions)):
cluster = self.partitions[i]
for j in range(len(cluster)):
ip, port = cluster[j].split(':')
port = int(port)
if (ip, port) == (self.ip, self.port):
self.cluster_index = i
self.server_index = j
else:
self.conns[i][j] = (ip, port)
self.current_term = 1
self.voted_for = -1
self.votes = set()
u = len(self.partitions[self.cluster_index])
self.state = 'FOLLOWER' if len(self.partitions[self.cluster_index]) > 1 else 'LEADER'
self.leader_id = -1
self.commit_index = 0
self.next_indices = [0]*u
self.match_indices = [-1]*u
self.election_period_ms = randint(1000, 5000)
self.rpc_period_ms = 3000
self.election_timeout = -1
print("Ready....")The assumption is that we will call the script using the following command:
python raft.py <IP> <PORT> <PARTITIONS>where <PARTITIONS> is the configuration as we saw above:
[['20.230.215.164:5001', '20.9.197.71:5001', '20.98.88.12:5001'], ['20.3.189.101:5001', '20.83.242.58:5001', '20.111.37.99:5001']]For using hash table, we have defined a HashTable class which is just an abstraction over the Python ‘dict’ library. Currently it just supports SET key and GET key operations.
class HashTable:
def __init__(self):
self.map = {}
self.lock = Lock()
def set(self, key, value, req_id):
with self.lock:
if key not in self.map or self.map[key][1] < req_id:
self.map[key] = (value, req_id)
return 1
return -1
def get_value(self, key):
with self.lock:
if key in self.map:
return self.map[key][0]
return NoneSimilarly CommitLog class is another abstraction for logging. It implements some common logging functionalities such as read, write, append etc.
class CommitLog:
def __init__(self, file='commit-log.txt'):
self.file = file
self.lock = Lock()
self.last_term = 0
self.last_index = -1
def get_last_index_term(self):
with self.lock:
return self.last_index, self.last_term
def log(self, term, command):
# Append the term and command to file along with timestamp
with self.lock:
with open(self.file, 'a') as f:
now = datetime.now().strftime("%d/%m/%Y %H:%M:%S")
message = f"{now},{term},{command}"
f.write(f"{message}\n")
self.last_term = term
self.last_index += 1
return self.last_index, self.last_term
def log_replace(self, term, commands, start):
# Replace or Append multiple commands starting at 'start' index line number in file
index = 0
i = 0
with self.lock:
with open(self.file, 'r+') as f:
if len(commands) > 0:
while i < len(commands):
if index >= start:
command = commands[i]
i += 1
now = datetime.now().strftime("%d/%m/%Y %H:%M:%S")
message = f"{now},{term},{command}"
f.write(f"{message}\n")
if index > self.last_index:
self.last_term = term
self.last_index = index
index += 1
# Truncate all lines coming after last command.
f.truncate()
return self.last_index, self.last_term
def read_log(self):
# Return in memory array of term and command
with self.lock:
output = []
with open(self.file, 'r') as f:
for line in f:
_, term, command = line.strip().split(",")
output += [(term, command)]
return output
def read_logs_start_end(self, start, end=None):
# Return in memory array of term and command between start and end indices
with self.lock:
output = []
index = 0
with open(self.file, 'r') as f:
for line in f:
if index >= start:
_, term, command = line.strip().split(",")
output += [(term, command)]
index += 1
if end and index > end:
break
return outputThe structure of the log file looks like:
19/12/2022 13:00:48,2,SET u 97402 0
19/12/2022 13:00:48,2,SET rozwe 20939 1
19/12/2022 13:00:48,2,SET dqgw 7630 2
19/12/2022 13:00:48,2,SET dqtcp 76385 3
19/12/2022 13:00:48,2,SET jw 55310 4
19/12/2022 13:00:48,2,SET uc 96046 5
19/12/2022 13:00:48,2,SET fnxq 31564 6
19/12/2022 13:00:48,2,SET nfosr 54319 7
19/12/2022 13:00:48,2,SET mjtsu 17336 8
19/12/2022 13:00:48,2,SET s 84298 9
19/12/2022 13:00:48,2,SET pgo 3461 10
19/12/2022 13:00:48,2,SET ybh 55434 1Timestamp, Term, Command
The line number in the log file serves as the index.
To store the ip and port for each server in the configuration, we are using a 2-D array ‘conns’. Each conns[i][j] where i-partition, j-server id or replica id in a partition i and the value is a tuple of (ip, port).
We define an utility file for defining all utility functions such as running threads, sending and receiving messages over sockets, retrying etc.
def run_thread(fn, args):
my_thread = Thread(target=fn, args=args)
my_thread.daemon = True
my_thread.start()
return my_thread
def wait_for_server_startup(ip, port):
while True:
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.connect((str(ip), int(port)))
return sock
except Exception as e:
traceback.print_exc(limit=1000)
def send_and_recv_no_retry(msg, ip, port, timeout=-1):
# Could not connect possible reasons:
# 1. Server is not ready
# 2. Server is busy and not responding
# 3. Server crashed and not responding
conn = wait_for_server_startup(ip, port)
resp = None
try:
conn.sendall(msg.encode())
if timeout > 0:
ready = select.select([conn], [], [], timeout)
if ready[0]:
resp = conn.recv(2048).decode()
else:
resp = conn.recv(2048).decode()
except Exception as e:
traceback.print_exc(limit=1000)
# The server crashed but it is still not marked in current node
conn.close()
return resp
def send_and_recv(msg, ip, port, res=None, timeout=-1):
resp = None
# Could not connect possible reasons:
# 1. Server is not ready
# 2. Server is busy and not responding
# 3. Server crashed and not responding
while True:
resp = send_and_recv_no_retry(msg, ip, port, timeout)
if resp:
break
if res is not None:
res.put(resp)
return resp‘rpc_period_ms’ is the timeout for sending and receiving messages from a remote server through socket. If timeout happens, we do retry.
def init(self):
# set initial election timeout
self.set_election_timeout()
# Check for election timeout in the background
utils.run_thread(fn=self.on_election_timeout, args=())
# Sync logs or send heartbeats from leader to all servers in the background
utils.run_thread(fn=self.leader_send_append_entries, args=())The init method sets the initial election timeout and also starts the background threads for checking election timeouts repeatedly and also if the server becomes leader, then repeatedly send heartbeats/log entries to other replicas.
def set_election_timeout(self, timeout=None):
# Reset this whenever previous timeout expires and starts a new election
if timeout:
self.election_timeout = timeout
else:
self.election_timeout = time.time() + randint(self.election_period_ms, 2*self.election_period_ms)/1000.0The election timeout is set to some random number for each replica. This is done to prevent all replicas to ‘wake’ up at the same time and starting election at the same time. This could lead to a situation where none of the replicas wins the election.
def on_election_timeout(self):
while True:
# Check everytime that state is either FOLLOWER or CANDIDATE before sending
# vote requests.
# The possibilities in this path are:
# 1. Requestor sends requests, receives replies and becomes leader
# 2. Requestor sends requests, receives replies and becomes follower again, repeat on election timeout
if time.time() > self.election_timeout and \
(self.state == 'FOLLOWER' or self.state == 'CANDIDATE'):
print("Timeout....")
self.set_election_timeout()
self.start_election()
def start_election(self):
print("Starting election...")
# At the start of election, set state to CANDIDATE and increment term
# also vote for self.
self.state = 'CANDIDATE'
self.voted_for = self.server_index
self.current_term += 1
self.votes.add(self.server_index)
# Send vote requests in parallel
threads = []
for j in range(len(self.partitions[self.cluster_index])):
if j != self.server_index:
t = utils.run_thread(fn=self.request_vote, args=(j,))
threads += [t]
# Wait for completion of request flow
for t in threads:
t.join()
return TrueWhen a Follower starts an election, it does the following:
- Update state to Candidate
- Increment current_term by 1
- Give vote to self and add self vote to set of all votes received
- Send vote requests to other replicas in the partition. This is done in ‘parallel’ threads (in Python it is not truly parallel).
def request_vote(self, server):
# Get last index and term from commit log
last_index, last_term = self.commit_log.get_last_index_term()
while True:
# Retry on timeout
print(f"Requesting vote from {server}...")
# Check if state if still CANDIDATE
if self.state == 'CANDIDATE' and time.time() < self.election_timeout:
ip, port = self.conns[self.cluster_index][server]
msg = f"VOTE-REQ {self.server_index} {self.current_term} \
{last_term} {last_index}"
resp = utils.send_and_recv_no_retry(msg, ip, port, timeout=self.rpc_period_ms/1000.0)
# If timeout happens resp returns None, so it won't go inside this condition
if resp:
vote_rep = re.match(
'^VOTE-REP ([0-9]+) ([0-9\-]+) ([0-9\-]+)$', resp)
if vote_rep:
server, curr_term, voted_for = vote_rep.groups()
server = int(server)
curr_term = int(curr_term)
voted_for = int(voted_for)
self.process_vote_reply(server, curr_term, voted_for)
break
else:
breakIn request vote, the current candidate server, first get the last index and last term from its commit log file and then sends a request to a replica with its current_term, last_index and last_term from its own log.
The purpose of the last index and last term will be clear soon.
If the response is not received within the ‘rpc_period_ms’ timeout, then we continue to retry until we succeed. Once we get the reply from the vote request, we process the request.
def process_vote_request(self, server, term, last_term, last_index):
print(f"Processing vote request from {server} {term}...")
if term > self.current_term:
# Requestor term is higher hence update
self.step_down(term)
# Get last index and term from log
self_last_index, self_last_term = self.commit_log.get_last_index_term()
# Vote for requestor only if requestor term is equal to self term
# and self has either voted for no one yet or has voted for same requestor (can happen during failure/timeout and retry)
# and the last term of requestor is greater
# or if they are equal then the last index of requestor should be greater or equal.
# This is to ensure that only vote for all requestors who have updated logs.
if term == self.current_term \
and (self.voted_for == server or self.voted_for == -1) \
and (last_term > self_last_term or
(last_term == self_last_term and last_index >= self_last_index)):
self.voted_for = server
self.state = 'FOLLOWER'
self.set_election_timeout()
return f"VOTE-REP {self.server_index} {self.current_term} {self.voted_for}"When a vote request arrives at a replica, it can be one of the following:
- A Leader, which did not send timely heartbeats or log APPEND requests to the Followers and thus some Follower ‘woke up’ and started election.
- A Candidate, because the election timeout of requestor and self are almost similar and hence both started election at same time.
The step_down method resets the replica:
def step_down(self, term):
print(f"Stepping down...")
# Revert to follower state
self.current_term = term
self.state = 'FOLLOWER'
self.voted_for = -1
self.set_election_timeout()… and also sets a new election timeout because now we are back again as Follower.
The current replica will not vote for a server whose log is less updated than own log. Because then it might happen that some non-updated server becomes new leader and thus we will lose some data because then the non-updated leader will try to make logs of other replicas same and thus delete more updated data from other replicas in that process.
First it checks if the term it receives is greater than own current_term. If it is so, then the replica will revert back to Follower (if it was Candidate or Leader before) because this server than cannot be a leader if some other server is more updated than own.
Note that we also reset voted_for variable, because it is associated with a term.
If the incoming term is greater than own term, it implies that the server has not voted for anyone else in the current term, and then it resets itself to current term.
If another requests come with term same as self, it will not vote for it.
Then it checks whether its own last term from commit log is smaller than the received last term or if they are equal then its own last index should be smaller or equal to the received last index.
If this is the case and the replica has not yet voted for anyone else, then this replica will give a vote to the requestor. This is again to ensure that this server only votes for a more updated server.
Also once it votes for another server, it cannot become Leader for current term (if it also started election) and hence its steps down.
def process_vote_reply(self, server, term, voted_for):
print(f"Processing vote reply from {server} {term}...")
# It is not possible to have term < self.current_term because during vote request
# the server will update its term to match requestor term if requestor term is higher
if term > self.current_term:
# Requestor term is lower hence update
self.step_down(term)
if term == self.current_term and self.state == 'CANDIDATE':
if voted_for == self.server_index:
self.votes.add(server)
# Convert to leader if received votes from majority
if len(self.votes) > len(self.partitions[self.cluster_index])/2.0:
self.state = 'LEADER'
self.leader_id = self.server_index
print(f"{self.cluster_index}-{self.server_index} became leader")
print(f"{self.votes}-{self.current_term}")When a requestor receives reply from another replica for its own vote request, it checks the term of the replier.
If the replier term was greater than own term, then the current server cannot contest for leader because it is not most updated and it steps down to Follower state again.
Else if the term is same, then it checks whether the replier voted for the current server. If it voted for current server, then it will add it to its own set of votes.
If the number of votes received by the current server is at-least (N+1)/2 where N is odd number and with N=3, it is 2, then the current server will become Leader.
The flow diagram for Log Replication looks like below:
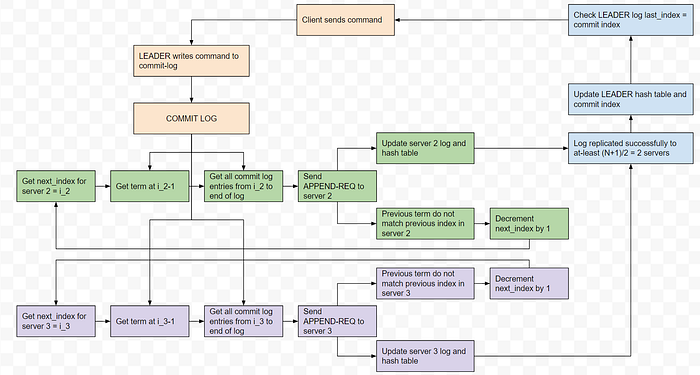
Again each color coding represents a parallel path and can be implemented in a different thread or process.
def leader_send_append_entries(self):
print(f"Sending append entries from leader...")
while True:
# Check everytime if it is leader before sending append queries
if self.state == 'LEADER':
self.append_entries()
# Commit entry after it has been replicated
last_index, _ = self.commit_log.get_last_index_term()
self.commit_index = last_index
def append_entries(self):
res = Queue()
for j in range(len(self.partitions[self.cluster_index])):
if j != self.server_index:
# Send append entries requests in parallel
utils.run_thread(fn=self.send_append_entries_request, args=(j,res,))
if len(self.partitions[self.cluster_index]) > 1:
cnts = 0
while True:
# Wait for servers to respond
res.get(block=True)
cnts += 1
# Once we get reply from majority of servers, then return
# and don't wait for remaining servers
# Exclude self
if cnts > (len(self.partitions[self.cluster_index])/2.0)-1:
return
else:
return‘leader_send_append_entries’ runs in a different thread. It checks if a leader is available, then it will send append entries from leader to all followers and eventually updates its commit index.
Append entries request is sent to all followers in parallel threads and once we obtain at-least (N+1)/2 acknowledgements, we consider the replication to be successful.
To collect the responses, we use a blocking Queue.
Whenever a follower successfully logs the leader’s entries, it updates the Queue with an entry. On the leader side, the queue is polled for new entries and once we have all the required entries we return.
def send_append_entries_request(self, server, res=None):
print(f"Sending append entries to {server}...")
# Fetch previous index and previous term for log matching
prev_idx = self.next_indices[server]-1
# Get all logs from prev_idx onwards, because all logs after prev_idx will be
# used to replicate to server
log_slice = self.commit_log.read_logs_start_end(prev_idx)
if prev_idx == -1:
prev_term = 0
else:
if len(log_slice) > 0:
prev_term = log_slice[0][0]
log_slice = log_slice[1:] if len(log_slice) > 1 else []
else:
prev_term = 0
log_slice = []
msg = f"APPEND-REQ {self.server_index} {self.current_term} {prev_idx} {prev_term} {str(log_slice)} {self.commit_index}"
while True:
if self.state == 'LEADER':
ip, port = self.conns[self.cluster_index][server]
resp = \
utils.send_and_recv_no_retry(msg, ip, port,
timeout=self.rpc_period_ms/1000.0)
# If timeout happens resp returns None, so it won't go inside this condition
if resp:
append_rep = re.match('^APPEND-REP ([0-9]+) ([0-9\-]+) ([0-9]+) ([0-9\-]+)$', resp)
if append_rep:
server, curr_term, flag, index = append_rep.groups()
server = int(server)
curr_term = int(curr_term)
flag = int(flag)
success = True if flag == 1 else False
index = int(index)
self.process_append_reply(server, curr_term, success, index)
break
else:
break
if res:
res.put('ok')Once a server becomes leader, it needs to send continuous messages to each follower, to make sure the follower knows that the leader is still alive.
Instead of sending additional heartbeat messages, the leader choses to send only the mismatched log entries to the followers so that the follower’s log is synced to the leader.
For this, each server maintains next_indices array where next_indices[i] corresponds to the index (or line number) in the i-th replica’s log from where the log of i-th replica and self log differs.
Knowing this index helps the leader because then the leader can only send logs to i-th replica starting from next_indices[i] to the last index instead of the entire log.
Each server needs to maintain the next_indices because any server can become leader.
Along with the logs starting from next_indices[i] to last index, the leader also sends the term at index next_indices[i]-1.
This term is used to verify that actually from next_indices[i] onwards the logs differ by matching the term at next_indices[i]-1 at leader with the term at next_indices[i]-1 at the i-th replica.
If the 2 terms matches, then the leader’s logs overwrites the i-th replica’s log starting from next_indices[i] onwards.
Else if the terms do not match, then the i-th follower rejects the append request and asks the leader to decrement the next_indices[i] by 1 and try again.
If the append request fails due to timeout we do retry until it succeeds.
def process_append_requests(self, server, term, prev_idx, prev_term, logs, commit_index):
print(f"Processing append request from {server} {term}...")
# Follower/Candidate received vote reply, reset election timeout
self.set_election_timeout()
flag, index = 0, 0
# If term < self.current_term then the append request came from an old leader
# and we should not take action in that case.
if term > self.current_term:
# Most likely term == self.current_term, if this server participated
# in voting rounds. If server was down during voting rounds and previous append requests, then term > self.current_term
# and we should update its term
self.step_down(term)
if term == self.current_term:
# Request came from current leader
self.leader_id = server
# Check if the term corresponding to the prev_idx matches with that of the leader
self_logs = self.commit_log.read_logs_start_end(prev_idx, prev_idx) if prev_idx != -1 else []
# Even with retries, this is idempotent
success = prev_idx == -1 or (len(self_logs) > 0 and self_logs[0][0] == prev_term)
if success:
# On retry, we will overwrite the same logs
last_index, last_term = self.commit_log.get_last_index_term()
if len(logs) > 0 and last_term == logs[-1][0] and last_index == self.commit_index:
# Check if last term in self log matches leader log and last index in self log matches commit index
# Then this is a retry and will avoid overwriting the logs
index = self.commit_index
else:
index = self.store_entries(prev_idx, logs)
flag = 1 if success else 0
return f"APPEND-REP {self.server_index} {self.current_term} {flag} {index}"Once the follower receives the append request from leader, if it had already started an election and became candidate, it will step down and reset to follower again.
store_entries functionality:
def store_entries(self, prev_idx, leader_logs):
# Update/Repair server logs from leader logs, replacing non-matching entries and adding non-existent entries
# Repair starts from prev_idx+1 where prev_idx is the index till where
# both leader and server logs match.
commands = [f"{leader_logs[i][1]}" for i in range(len(leader_logs))]
last_index, _ = self.commit_log.log_replace(self.current_term, commands, prev_idx+1)
self.commit_index = last_index
# Update state machine
for command in commands:
self.update_state_machine(command)
return last_indexThe follower does not blindfoldedly applies the leader’s logs to itself.
It first checks if the term at prev_idx matches with prev_term from leader. If they match, then it applies the leader’s logs else, it will reject the request. Thus the leader will now have to update the prev_idx so that the term at prev_idx matches.
This is done in order to ensure safety property of Raft:
If 2 servers have same term and command at index i, then all terms and commands from index 0 to i-1 are also equal.
def process_append_reply(self, server, term, success, index):
print(f"Processing append reply from {server} {term}...")
# It cannot be possible that term < self.current_term because at the time of append request,
# all servers will be updated to current term
if term > self.current_term:
# This could be an old leader which become active and sent
# append requests but on receiving higher term, it will revert
# back to follower state.
self.step_down(term)
if self.state == 'LEADER' and term == self.current_term:
if success:
# If server log repaired successfully from leader then increment next index
self.next_indices[server] = index+1
else:
# If server log could not be repaired successfully, then retry with 1 index less lower than current next index
# Process repeats until we find a matching index and term on server
self.next_indices[server] = max(0, self.next_indices[server]-1)
self.send_append_entries_request(server)Once the leader receives the reply for the append request from follower i (along with term of the follower and the last synced index) depending on whether the sync was successful or not, the leader will either update the next_indices[i] to index+1 (if successful) or decrement by 1 (if unsuccessful).
If it was unsuccessful, leader retries again with follower i.
‘index’ is the last synced index by the follower following the leader’s append request.
The ‘decrement and retry’ operation continues till we find an index in both the logs where the term matches (and by safety property all previous terms matches).
Why does the leader do not know what is the correct next_indices[i] ?
Say in term T, the leader was A and the follower was C. Leader A has the correct next_indices for both B and C. But B may not have the correct next_indices for A or C.
This is because only the leader is updated about next_indices in a given term.
Now at term T+1, when B becomes the new leader, then it may not have correct next_indices for C.
The possibilities are as follows:
The array is the sequence of terms in the commit log of B and C respectively.
B=[1,1,1,2,2,2,3,3] (leader)
C=[1,1,1,2,2]
next_indices[C]=5In this case, B only needs to send the last 3 entries [2,3,3] once to C.
Another possibility is:
B=[1,1,1,2,2,2,3,4] (leader)
C=[1,1,1,3,3]
next_indices[C]=5In this case, when B sends the last 3 entries and the prev_term=2 at prev_index=4, there is a mismatch because B[4] != C[4], thus C rejects B’s append request and B decrements next_indices[C] by 1 to 4.
But again B[3] != C[3], and C rejects and B decrements again: next_indices[C]=3. This time there is a match and thus B sends the log entries [2,2,2,3,3] to C.
Another possibility is:
B=[1,1,1,2,2,2,3,4] (leader)
C=[1,1,1,3,3]
next_indices[C]=2In this B only needs to send the log entries starting from index 2 onwards i.e. [1,2,2,2,3,4] to C once since there is a match B[1] == C[1].
Another possibility is:
B=[1,1,1,5,5,5,6,6] (leader)
C=[1,1,1,2,2,2,3,3,3,4,4]
next_indices[C]=5This can be a valid scenario when B was down during the terms 2, 3 and 4 and only A and C operational.
From 5th term onwards, only A and B were operational. In the current term i.e. 7, A is not operational but only B and C and since the last term of B is 6 > last term of C i.e. 4, B became the leader with votes from B and C.
Again in this case, decrement and retry operation will take place till next_indices[C]=3.
Can this be a valid scenario ?
B=[1,1,1,2,2,2,3,3] (leader)
C=[1,1,1,4,4,4,5,5,5,6,6]
next_indices[C]=5This cannot be a valid scenario because if B is the leader, then its last term should be greater than 6 (C’s last term). B will not receive majority votes in this case.
Does data loss happens in Raft protocol?
Whenever client sends a SET command to the leader of a partition, the leader will follow the following steps:
- Add the command along with the term in its own commit log file.
- Replicate the command and any pending commands from previous terms to all followers.
- Followers will sync their commit logs from leader’s append request and also update their own hash tables.
- Followers will acknowledge the leader
- Once leader receives majority acknowledgements from followers, update its own hash table.
- Leader sends reply to client
It can happen that:
- Leader crashes after adding the command(s) to its log but before sending to the followers. Command is not commited.
- Majority followers are not working i.e. only 2 out of 5 replicas are operational. Command is not commited.
- Due to network partitions, response from majority followers did not reach the leader. Command is commited but leader hash table not updated.
- … and so on.
The client will either wait indefinitely for the command to succeed or the leader (if alive) will send timeout to client.
If the client does not retry, then the command is lost, since if a new leader is chosen in the next term, and the command was not replicated to this new leader, then the new leader will overwrite the old leader’s log with its own.
How to handle conflicting entries due to retry operations?
Client sends X=“SET A 10” at time T and command Y=“SET A 12” at time T+1. Now command X failed (due to above reasons) and client is retrying X in a different thread and command Y succeeded in a different thread. The time at which X succeeds is T+2. But since Y is more recent but it succeeded at time T+1, Y will be overwritten by X in the hash table.
To avoid such a scenario, we pass a request id or timestamp from client along with the command: “SET A 10 <T>” and “SET A 12 <T+1>”
During retry when we see that we already have an entry in the hash table with more recent timestamp for the same key, then we do not update the hash table for that key.
But we cannot guarantee ordering with different clients.
“SET A 10 12:30PM” from client P might be more recent that “SET A 12 12:32PM” from client Q if the clock at Q’s end is running faster by more than 2 minutes. Actual time at Q’s end must be 12:29PM.
What happens when an old leader becomes active?
When the leader for term T, gets busy, it might delay sending the append requests to the followers and as a result some follower will initiate a new election for term T+1 and since the old leader is busy, some other server will win the election with majority votes.
The new leader will start sending the append requests now to the followers. But it might happen that the old leader is no more busy and again starts sending append requests.
But note that the term for append request from old leader is still T whereas the current term in all other servers is T+1. So the followers will reject the old leader’s append request as its term is lower and on receiving the append replies with rejection, the old leader will convert to a follower.
def process_append_reply(self, server, term, success, index):
print(f"Processing append reply from {server} {term}...")
# It cannot be possible that term < self.current_term because at the time of append request,
# all servers will be updated to current term
if term > self.current_term:
# This could be an old leader which become active and sent
# append requests but on receiving higher term, it will revert
# back to follower state.
self.step_down(term)How does majority vote ensure best leader selection?
Let’s say we have 5 servers in a partition A, B, C, D and E.
In a given term T, if the leader is A, then it must have successfully synced its logs with at-least 2 other servers say B and C, but it is not guaranteed that D and E have also synced their logs with A. Thus the last term of both B and C are T. Assume that last term of D and E is < T.
In the event that A is unavailable, we need to choose a new leader. But that new leader should be updated because if it is not, then due to leader log syncing it will overwrite data in the followers logs with its own and thus it will lead to loss in data or inconsistency.
During the next voting term T+1, can D or E receive majority votes?
If A is unavailable, then A will not vote, but B and C will never vote for D or E as their last term < T. So even if D votes for itself and also E votes for D, it will receive only 2 out of 4 votes (which is non-majority).
What for B or C ? If B votes for itself and also both D and E, then B will win. C need not vote for B. Similarly for C. It can also win by receiving at-least 3 votes.
But if both B and C starts election at the same time, then there is high probability that they receive 2 votes each (B, D) votes for B and (C, E) votes for C.
Either re-election will happen or if A joins back it’s vote will be the tie-breaker.
Why do we need randomized election timeouts?
If the election timeout is same for all servers, then all servers will start election at the same time and will only vote for itself, hence we will never have a leader by majority votes.
What are the performance implications of the above implementation?
There are several performance implications in the above codes, just to list a few major:
- During append requests by leader, it first reads the log file to get the next log entries for each follower and then sends the log entries over network to followers and each follower then updates its own log files.
Depending on how many log entries are sent over, this can have too many I/O operations — firstly disk reads, then network I/O then disk write I/O.
Assuming each log entry is 40 bytes in size, and if we are sending on an average 10 entries to each of the 4 followers i.e. around 2 kilobytes of data. If the number of requests are 100K per second, then in order to keep up with the request we need to do throughput of at-least 200MB per second.
Disk write operations are also not sequential. We overwrite existing logs data in followers to match leader’s log sequence.
- In the event when the follower’s prev_term in log did not match with the leader’s, we need to do decrement and retry operation several times till a match is found.
We can replace multiple retries with a single retry, by computing the first index of mismatch at follower and sending that index to the leader and then the leader again sending the log entries from that index onwards.
- Due to the Global Interpreter Lock, only one thread runs at a time in Python even if there are multiple cores. Thus Raft becomes too slow to be implemented in Python because there are several threads that needs to be run in parallel for e.g. handling SET and GET commands, leader sending append requests, vote requests etc.
- The size of the commit log file will become unmanageable at a certain point in time because we store every command seen, in this log. Thus reading and writing can be time consuming because each read is a sequential O(N) time complexity.
One possible approach for doing log compaction:
- Whenever the size of a log file increases beyond say 10K entries, create a snapshot of the log data i.e. each key will have multiple entries in the log with a different term and timestamp, but we only consider the last entry for each key i.e. the latest state of a key.
- New logs are then written to a new commit log file until we again hit the limit of 10K entries, when we create a new snapshot file.
- Merge the new and the old snapshot file into a single snapshot file.
Will explore log compaction in details in the next post.
The full code is available on my github repository: funktor/distributed-hash-table at raft (github.com)
References:
